Model HQ by LLMWare.ai: Run language models and use AI agents on Snapdragon X Series devices


Sign up for Developer monthly newsletter
Join thousands of developers around the globe who receive latest news and updates from our monthly curated newsletter.
Sign up
Come for support, stay for the community
Get support from experts, connect with like-minded developers, and access exclusive virtual events.
Join Developer DiscordRunning LLMs on device has two issues: memory footprint and efficiency. To address both problems, LLMWare’s Model HQ provides a fast, efficient on-ramp to deploying and managing Gen AI models on local devices. Model HQ makes it easier to use specialized language models locally for use cases like retrieval-augmented generation (RAG) and AI agents.
Now, LLMWare’s Model HQ is available on devices with Snapdragon X Series processors. With Model HQ, AI PCs powered by Snapdragon X Series processors can deliver powerful, secure, ready-to-use AI directly on their devices, including inference on the Qualcomm Hexagon NPU.
Small language models for enterprises. Why and why now?
Did you know that up to 99% of AI workflows can be performed by small language models? SLMs are efficient AI models ranging from 1B to 32B parameters that can run even on laptops. While most of the high-profile uses of AI in the last few years have involved large-frontier LLMs with up to 1.8 trillion parameters and tremendous cloud compute, most enterprise use cases are not that demanding. Recent advancements in hardware, such as AI PCs powered by Snapdragon X Series processors, coupled with significant advancements in SLM capabilities (Phi-4 and Qwen), allow enterprises to deliver AI productivity enhancements directly at the user level, on devices that can run without Wi-Fi.
LLMWare.ai empowers enterprises with a secure, scalable, cost-effective AI solution designed for local deployments. Unlike traditional AI models that rely on costly and insecure API connections, LLMWare’s Model HQ keeps your AI where your data lives—even on laptops—ensuring maximum security and compliance.
With 30+ proprietary SLMs and 90+ optimized models (including Gemma, Llama, Phi and Mistral), LLMWare’s Model HQ eliminates costly inference fees, reducing AI costs to as low as $0 per token for laptop inferencing.
Model HQ’s no-code, point-and-click client app enables enterprises to easily use AI workflows, automate tasks and enhance productivity with out-of-the-box capabilities that include:
- Chat with AI models
- Text-to-SQL queries
- Image tagging and classification
- Document search and analysis with RAG
Model HQ allows business users to access AI for tasks like analyzing complex contracts, performing SQL queries in natural language and answering questions about earnings statements. It significantly enhances productivity, all while ensuring security and privacy with no data leaving the device.

Private AI running on a PC or laptop
High-profile, first-gen applications of AI have left the impression that you need to have as much processing power as possible for AI. That’s the kind of assumption that developers and software engineers live to debunk, and LLMWare enables them to do that with Model HQ.
Naturally, if you have a device with Snapdragon X Series device with the Hexagon NPU – you can offload your AI processing work from CPU and GPU. But SLMs make it possible to run inference even on a local device that isn’t an AI PC and doesn’t have a GPU or NPU.
With Model HQ, even on a local device with only a CPU, you can use AI models as large as 32 billion parameters on Snapdragon X-powered laptops. And the GPU and NPU available on Snapdragon X processors optimize their performance.
Running AI workloads on devices with Snapdragon X Series devices is a big step toward more-personalized, secure AI use cases. You enjoy the privacy and security of running on device without shuttling data to and from the cloud. Model HQ equips you for compliance, with logs for auditing and AI explainability.
Model HQ on laptops with Snapdragon X Series series
LLMWare makes it easy for users to access more than 90 of the latest SLMs on Snapdragon X Series including:
- Qwen 2.5-32B
- Qwen 2.5-7B-Coder
- Llama 3-8B
- Phi-4
- Gemma 2-27B
- Gemma 2-9B
- Mistral Small-22B
- Mistral-7B
- Yi 6B
- Yi 9B
- Dragon RAG-specialized models
- SLIM Function-calling models for agent workflows
With the rapid advancements in language models, LLMWare will continually update their model catalog to deliver easy and private access to the best new SLMs to run devices with Snapdragon X Series, specifically on the Qualcomm Hexagon NPU.
That means you can use Model HQ on device with Snapdragon X Series for applications like chatbots, text-to-SQL reading, image reading, coding assistants, voice transcription and document analysis (PDF, DOCX, PPTX).
Model HQ uses the Qualcomm AI Stack, which includes the AI libraries, tools and SDK needed to take full advantage of the Qualcomm Hexagon NPU on the Snapdragon X Series. With the Qualcomm AI Stack, you can develop once and deploy on virtually all Qualcomm Technologies products.
With the rapid advancements in language models, LLMWare continuously updates their model catalog. They plan to continue their work with Qualcomm Technologies to expand the list of models that run on devices with Snapdragon X Series, specifically on the Qualcomm Hexagon NPU.
LLMWare x Qualcomm
Feb 26, 2025 | 2:24
Try it out
If you’re working on bringing AI in house – especially if you’re in a highly regulated or data-sensitive industry – then you want private, secure AI that you control. LLMWare’s expertise in deploying agentic AI applications and fine-tuning SLMs is a smart avenue to pursue, even more so now that Model HQ supports Snapdragon X Series laptops.
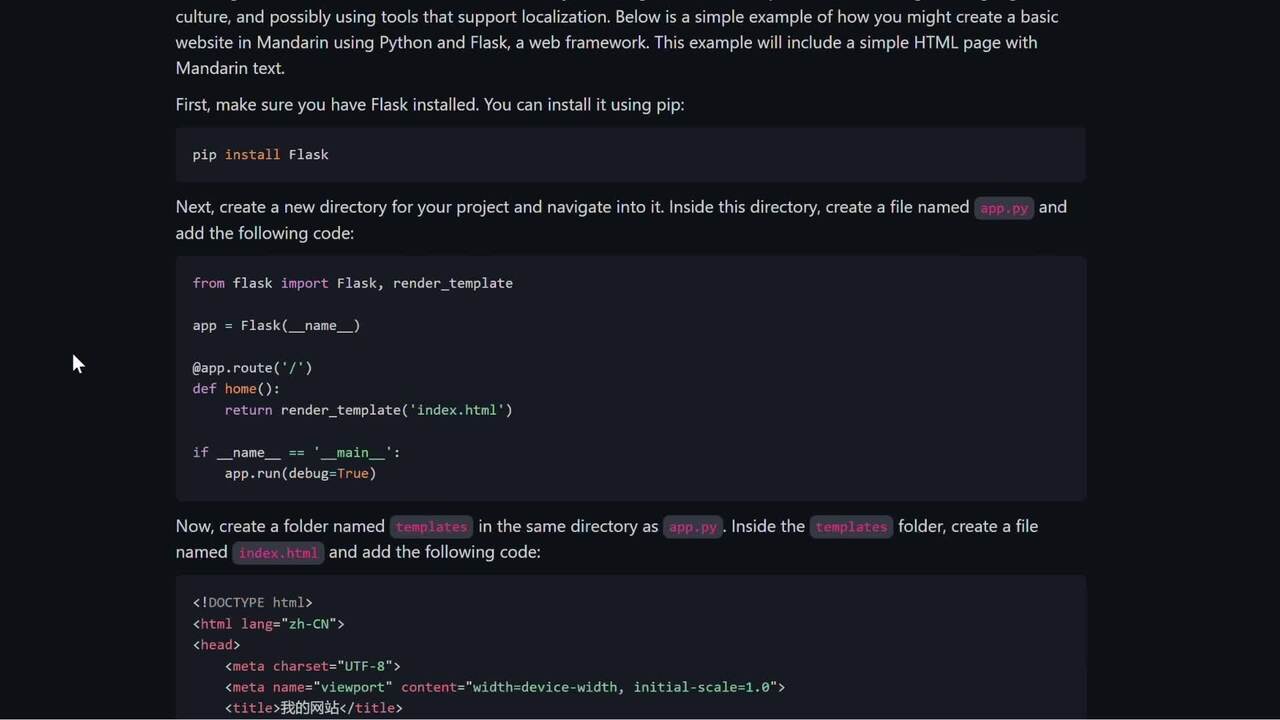
In addition to providing out-of-the box capabilities for on-device AI, Model HQ makes it easy for in-house developers to create lightweight AI applications using LLMWare’s GitHub repo. In the repo you’ll find a “Getting Started” section with a pip3 install llmware ready for you to try out on Snapdragon X Series devices. And have a look at LLMWare’s YouTube channel to get started with agents using function-calling models.
Planning to attend Mobile World Congress in Barcelona? Look for LLMWare at our booth 3E10 from March 3 through March 6.
You can also join us virtually on March 5 for the webinar "On-Device AI deployment with ONNX Runtime & Copilot+ PCs powered by Snapdragon" to learn more about LLMWare and watch live demo.
Learn more about the collaboration between LLMWare and Qualcomm on Snapdragon X Series.