
If you missed the Snapdragon 8 Gen 2 Mobile Platform announcement at last year’s Snapdragon Summit, here’s your chance to hear some of the most exciting highlights via our recorded live stream. You’ll notice a lot of artificial intelligence (AI) mentions throughout the three-day event — and the one leading the pack is our most powerful AI Engine shipped to date, right inside the Snapdragon 8 Gen 2 mobile platform.
Let’s take a deep dive into the most significant performance and power-efficient technology innovations we made for this year’s Qualcomm AI Engine.

Dedicated power delivery system
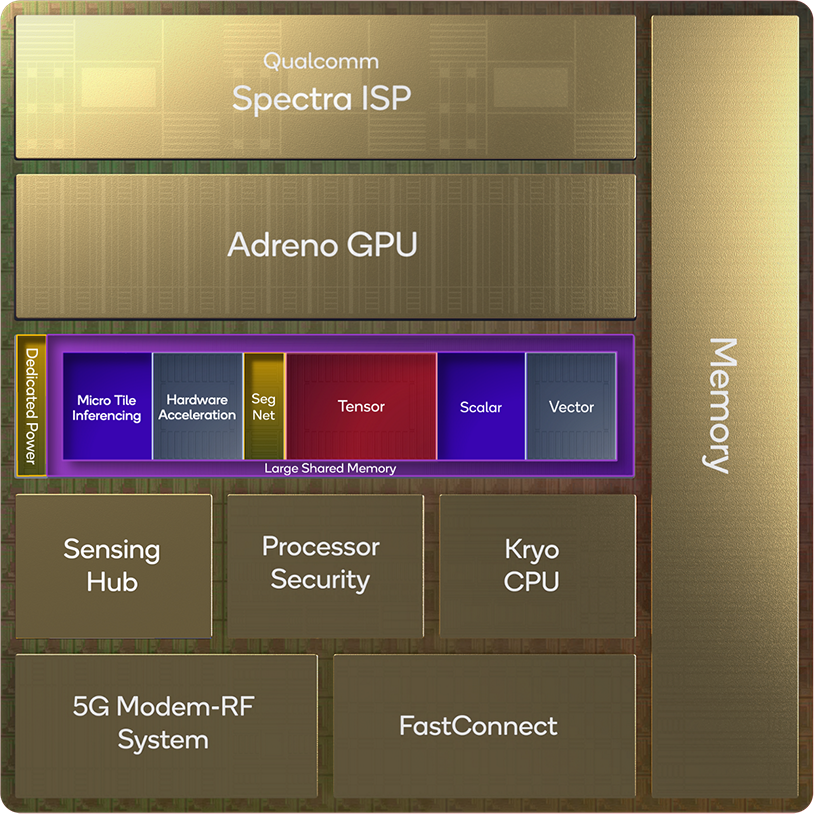
Our architectural improvements on the Qualcomm Hexagon processor for Snapdragon 8 Gen 2 include a dedicated power delivery system, which is like upgrading the electrical breaker system in your house. Now, the Hexagon processor has its own breaker with a dedicated power delivery system. This allows us to freely transfer certain amounts of power to Hexagon to adapt to its workload — cranking up performance for heavy workloads or reducing power consumption for extreme power savings.
Micro tile inferencing
Micro tile inferencing is an industry-first approach to boost AI performance at ultra-low power. A conventional way of inferencing a deep-learning neural network is to load one entire network into Hexagon, run through one layer of the network, then write to double data rate (DDR) memory, then read the second layer, run, write to DDR, and repeat.
This method requires read and write to DDR for every layer in the network. With a bigger neural network (NN) that has multiple layers, this becomes a very expensive operation that can drain a lot of power. This method also lacks utilization of all the accelerators, as only one of the three accelerators (scalar, vector, and tensor) of the processor is active at a time.
Another way the industry is addressing the memory issue is a technique called depth-first acceleration. The concept is based on slicing up the NN layers into smaller tiles, executing multiple layers on one tile, and then reading out to memory. This eliminates the intermediate reads and writes to DDR memory.
Micro tile inferencing is a new technique, made possible by the latest Hexagon processor. Because of the large amount of closely coupled control processing available in the scalar accelerator, we can slice neural network layers into even smaller micro tiles — allowing us to speed up the inferencing process of deep and complex neural networks and achieve even better power savings. The Hexagon processor has enough control processing capability to crack a single network into tens of thousands of micro tiles. By running multiple micro tiles simultaneously, the scalar, vector, and tensor accelerators are all put to work at the same time, combining as many as 10 or more layers to eliminate almost all the intermediate memory reads and writes. Micro-tile acceleration is hardware accelerated on the Hexagon processor and works with any neural network that’s being inferenced.
Micro Tile Inferencing
Nov 18, 2022 | 0:23
Speeding up transformer networks
Along with micro tile inferencing, we've accelerated activation functions and group convolutions, and doubled the performance of the Tensor accelerator. With all this prep work, we can now tackle even harder and more complex neural networks, such as transformer networks — a complex network that learns context by tracking relationships in sequential data. It has a variety of applications such as language translation, transcription, and improved image segmentation in camera use cases, which you use every day. With our large ecosystem in the mobile space, more and more applications are adopting the transformer network.
INT4 support
We have successfully transformed deep learning models from FP32 to INT16 and INT8, maintaining accuracy while reducing memory consumption. Snapdragon 8 Gen 2 is the industry’s first processor to commercialize INT4, providing an additional 60% power saving and 90% performance increase with dedicated hardware support. See an example of this in the following video, illustrating how difficult it is to tell the difference between the two videos. With INT4 we can preserve almost the same amount of video quality and resolution, but at 60% or more power savings, so you can do more AI without draining battery life.
Arcsoft INT4 vs INT8
Nov 11, 2022 | 0:12

Hexagon direct link
On the Snapdragon 8 Gen 2, we doubled the physical link between the Hexagon processor and the Qualcomm Spectra ISP and Qualcomm Adreno GPU, driving higher bandwidth and lower latency to create new use cases like the Cognitive-ISP or super resolution in gaming scenarios. With these new and faster links, we can reduce the dependency on the system DDR memory when moving around AI data and make Hexagon more directly coupled with the Qualcomm Spectra ISP and the Adreno GPU.
Hexagon Direct Link
Nov 11, 2022 | 0:11

On-device AI: Qualcomm is leading the way
We are proud to have shipped more than 2 billion AI-capable products to date: This marks Qualcomm Technologies, Inc. as one of the biggest AI-product companies in the world and the AI Inferencing leader at the edge. I invite you to join us as we continue to pave the way for groundbreaking AI in mobile devices and beyond.
